563 lines
21 KiB
Python
563 lines
21 KiB
Python
|
|
#!/usr/bin/env python
|
||
|
|
# coding: utf-8
|
||
|
|
|
||
|
|
# # Introduction & Import Necessary Setup
|
||
|
|
# In this labsheet, we'll delve into the fascinating world of autoencoders (AEs), a type of neural network renowned for its ability to compress and reconstruct data. Autoencoders work by first encoding input data, such as images, into a compact feature vector through an encoder network. This process effectively distills the essence of the data into a smaller, more manageable form. The feature vector, often referred to as the "bottleneck," plays a crucial role in this compression process, allowing us to represent the input data with fewer features.
|
||
|
|
#
|
||
|
|
# Following compression, a second neural network, known as the decoder, takes over to reconstruct the original data from the compressed feature vector. This remarkable ability to compress and then reconstruct data makes autoencoders extremely valuable in various applications, including data compression and image comparison at a more meaningful level than mere pixel-by-pixel analysis.
|
||
|
|
#
|
||
|
|
# Moreover, our exploration will not stop at the autoencoder framework itself. We will also introduce the concept of "deconvolution" (also known as transposed convolution), a powerful operator used to enlarge feature maps in both height and width dimensions. Deconvolution networks are indispensable in scenarios where we begin with a compact feature vector and aim to generate a full-sized image. This technique is pivotal in various advanced neural network applications, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and super-resolution.
|
||
|
|
#
|
||
|
|
# To kick things off, we'll start by importing our standard libraries, setting the stage for our deep dive into the inner workings and applications of autoencoders.
|
||
|
|
|
||
|
|
# In[1]:
|
||
|
|
|
||
|
|
|
||
|
|
## Standard libraries
|
||
|
|
import os
|
||
|
|
import json
|
||
|
|
import math
|
||
|
|
import numpy as np
|
||
|
|
|
||
|
|
## Imports for plotting
|
||
|
|
import matplotlib.pyplot as plt
|
||
|
|
get_ipython().run_line_magic('matplotlib', 'inline')
|
||
|
|
from IPython.display import set_matplotlib_formats
|
||
|
|
set_matplotlib_formats('svg', 'pdf') # For export
|
||
|
|
from matplotlib.colors import to_rgb
|
||
|
|
import matplotlib
|
||
|
|
matplotlib.rcParams['lines.linewidth'] = 2.0
|
||
|
|
## Progress bar
|
||
|
|
from tqdm.notebook import tqdm
|
||
|
|
|
||
|
|
## PyTorch
|
||
|
|
import torch
|
||
|
|
import torch.nn as nn
|
||
|
|
import torch.nn.functional as F
|
||
|
|
import torch.utils.data as data
|
||
|
|
import torch.optim as optim
|
||
|
|
# Torchvision
|
||
|
|
import torchvision
|
||
|
|
from torchvision.datasets import CIFAR10
|
||
|
|
from torchvision import transforms
|
||
|
|
|
||
|
|
DATASET_PATH = "dataset"
|
||
|
|
|
||
|
|
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
|
||
|
|
print("Device:", device)
|
||
|
|
|
||
|
|
|
||
|
|
# # Download and setup the dataset
|
||
|
|
# In this labsheet, our focus shifts to the CIFAR10 dataset, a collection known for its rich, colored images. Each image within CIFAR10 is equipped with 3 color channels and boasts a resolution of 32x32 pixels. This characteristic is particularly advantageous when working with autoencoders, as they are not bound by the constraints of probabilistic image modeling.
|
||
|
|
#
|
||
|
|
# Should you already have the CIFAR10 dataset downloaded in a different directory, it's important to adjust the DATASET_PATH variable accordingly. This step ensures you avoid unnecessary additional downloads, streamlining your workflow and allowing you to dive into the practical exercises more swiftly.
|
||
|
|
|
||
|
|
# In[105]:
|
||
|
|
|
||
|
|
|
||
|
|
# Transformations applied on each image => only make them a tensor
|
||
|
|
transform = transforms.Compose([transforms.ToTensor(),
|
||
|
|
transforms.Normalize((0.5,),(0.5,))])
|
||
|
|
|
||
|
|
# Loading the training dataset. We need to split it into a training and validation part
|
||
|
|
train_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=transform, download=True)
|
||
|
|
train_set, val_set = torch.utils.data.random_split(train_dataset, [45000, 5000])
|
||
|
|
|
||
|
|
# Loading the test set
|
||
|
|
test_set = CIFAR10(root=DATASET_PATH, train=False, transform=transform, download=True)
|
||
|
|
|
||
|
|
# We define a set of data loaders that we can use for various purposes later.
|
||
|
|
train_loader = data.DataLoader(train_set, batch_size=256, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
|
||
|
|
val_loader = data.DataLoader(val_set, batch_size=256, shuffle=False, drop_last=False, num_workers=4)
|
||
|
|
test_loader = data.DataLoader(test_set, batch_size=256, shuffle=False, drop_last=False, num_workers=4)
|
||
|
|
|
||
|
|
def get_train_images(num):
|
||
|
|
return torch.stack([train_dataset[i][0] for i in range(num)], dim=0)
|
||
|
|
|
||
|
|
|
||
|
|
# # Building the autoencoder
|
||
|
|
#
|
||
|
|
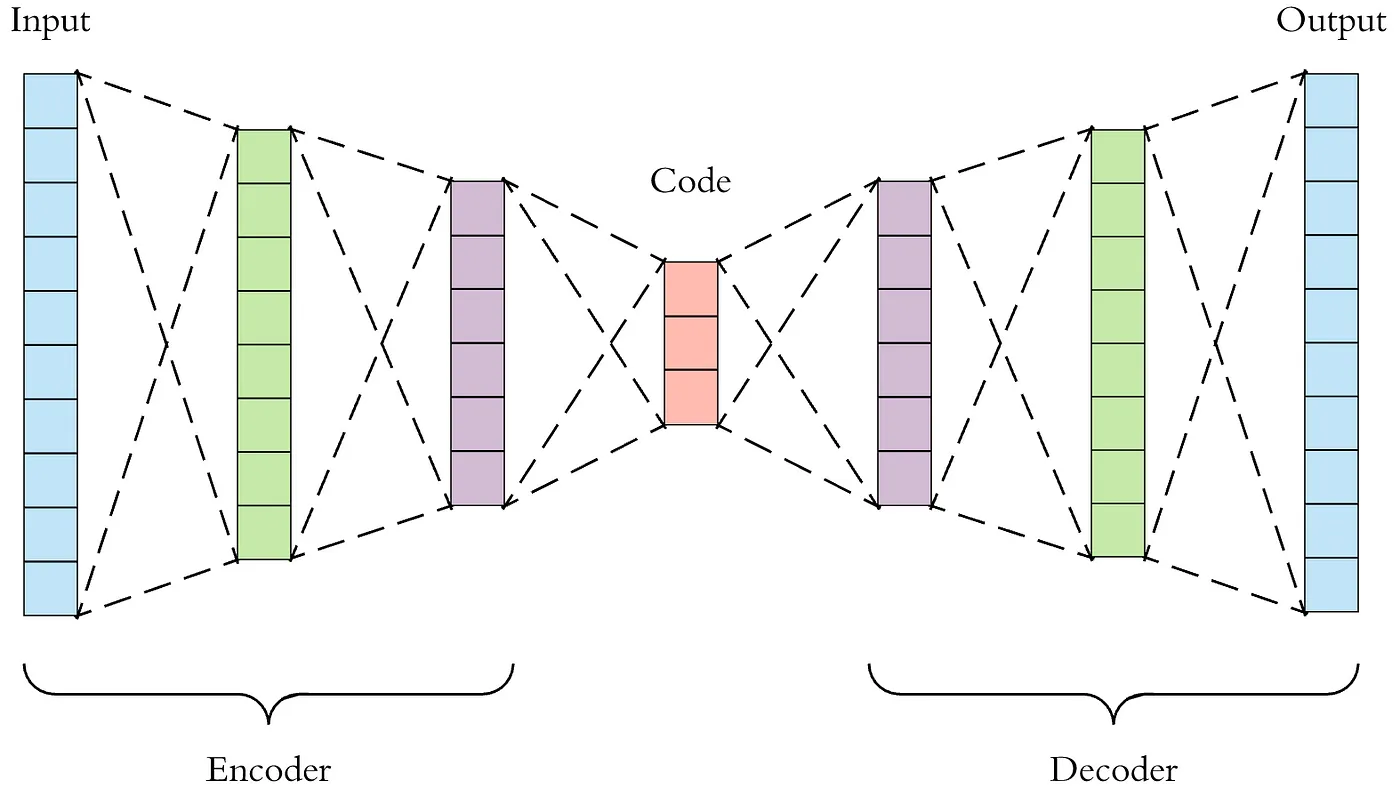
# In general, an autoencoder consists of an **encoder** that maps the input $x$ to a lower-dimensional feature vector $z$, and a **decoder** that reconstructs the input $\hat{x}$ from $z$. We train the model by comparing $x$ to $\hat{x}$ and optimizing the parameters to increase the similarity between $x$ and $\hat{x}$. See below for a small illustration of the autoencoder framework.
|
||
|
|
#
|
||
|
|
#
|
||
|
|
# 
|
||
|
|
|
||
|
|
#
|
||
|
|
# For an educational purpose revision in markdown format, the text could be enhanced as follows:
|
||
|
|
#
|
||
|
|
# To kick off our exploration, we initiate with the construction of the encoder. This component is fundamentally a deep convolutional network tailored for progressively diminishing the image's dimensions. This diminution is achieved through the use of strided convolutions, which methodically reduce the image's size layer by layer. Following the thrice-executed downscaling process, we transition the architecture from convolutional layers to a flattened feature representation. This is achieved by flattening the spatial features into a single vector, which is then processed through several linear layers. As a result, we obtain the latent representation, denoted as
|
||
|
|
# $z$, encapsulating the compressed essence of the input image. The size of this latent vector, $d$, is adjustable, providing flexibility in the encoding capacity of our network.
|
||
|
|
|
||
|
|
# In[59]:
|
||
|
|
|
||
|
|
|
||
|
|
class Encoder(nn.Module):
|
||
|
|
|
||
|
|
def __init__(self,
|
||
|
|
num_input_channels : int,
|
||
|
|
base_channel_size : int,
|
||
|
|
latent_dim : int,
|
||
|
|
act_fn : object = nn.GELU):
|
||
|
|
"""
|
||
|
|
Inputs:
|
||
|
|
- num_input_channels : Number of input channels of the image. For CIFAR, this parameter is 3
|
||
|
|
- base_channel_size : Number of channels we use in the first convolutional layers. Deeper layers might use a duplicate of it.
|
||
|
|
- latent_dim : Dimensionality of latent representation z
|
||
|
|
- act_fn : Activation function used throughout the encoder network
|
||
|
|
"""
|
||
|
|
super().__init__()
|
||
|
|
c_hid = base_channel_size
|
||
|
|
self.net = nn.Sequential(
|
||
|
|
nn.Conv2d(num_input_channels, c_hid, kernel_size=3, padding=1, stride=2), # 32x32 => 16x16
|
||
|
|
act_fn(),
|
||
|
|
nn.Conv2d(c_hid, c_hid, kernel_size=3, padding=1),
|
||
|
|
act_fn(),
|
||
|
|
nn.Conv2d(c_hid, 2*c_hid, kernel_size=3, padding=1, stride=2), # 16x16 => 8x8
|
||
|
|
act_fn(),
|
||
|
|
nn.Conv2d(2*c_hid, 2*c_hid, kernel_size=3, padding=1),
|
||
|
|
act_fn(),
|
||
|
|
nn.Conv2d(2*c_hid, 2*c_hid, kernel_size=3, padding=1, stride=2), # 8x8 => 4x4
|
||
|
|
act_fn(),
|
||
|
|
nn.Flatten(), # Image grid to single feature vector
|
||
|
|
nn.Linear(2*16*c_hid, latent_dim)
|
||
|
|
)
|
||
|
|
|
||
|
|
# self.flatten = nn.Sequential(
|
||
|
|
# nn.Flatten(), # Image grid to single feature vector
|
||
|
|
# nn.Linear(2*16*c_hid, latent_dim)
|
||
|
|
# )
|
||
|
|
|
||
|
|
def forward(self, x):
|
||
|
|
# x = self.net(x)
|
||
|
|
|
||
|
|
# print(x.shape)
|
||
|
|
|
||
|
|
# return self.flatten(x)
|
||
|
|
|
||
|
|
return self.net(x)
|
||
|
|
|
||
|
|
|
||
|
|
# # Task1
|
||
|
|
# Now Complete the decoder implementation
|
||
|
|
|
||
|
|
# In[133]:
|
||
|
|
|
||
|
|
|
||
|
|
class Decoder(nn.Module):
|
||
|
|
|
||
|
|
def __init__(self,
|
||
|
|
num_input_channels : int,
|
||
|
|
base_channel_size : int,
|
||
|
|
latent_dim : int,
|
||
|
|
act_fn : object = nn.GELU):
|
||
|
|
"""
|
||
|
|
Inputs:
|
||
|
|
- num_input_channels : Number of channels of the image to reconstruct. For CIFAR, this parameter is 3
|
||
|
|
- base_channel_size : Number of channels we use in the last convolutional layers. Early layers might use a duplicate of it.
|
||
|
|
- latent_dim : Dimensionality of latent representation z
|
||
|
|
- act_fn : Activation function used throughout the decoder network
|
||
|
|
"""
|
||
|
|
super().__init__()
|
||
|
|
c_hid = base_channel_size
|
||
|
|
self.net = nn.Sequential(
|
||
|
|
nn.Linear(latent_dim, 2*16*c_hid),
|
||
|
|
act_fn(),
|
||
|
|
nn.Unflatten(1, (2*c_hid, 4, 4)),
|
||
|
|
nn.ConvTranspose2d(2*c_hid, 2*c_hid, kernel_size=3, padding=1, stride=2, output_padding=1), # 8x8 <= 4x4
|
||
|
|
act_fn(),
|
||
|
|
nn.Conv2d(2*c_hid, 2*c_hid, kernel_size=3, padding=1),
|
||
|
|
act_fn(),
|
||
|
|
nn.ConvTranspose2d(2*c_hid, c_hid, kernel_size=3, padding=1, stride=2, output_padding=1), # 16x16 <= 8x8
|
||
|
|
act_fn(),
|
||
|
|
nn.Conv2d(c_hid, c_hid, kernel_size=3, padding=1),
|
||
|
|
act_fn(),
|
||
|
|
nn.ConvTranspose2d(c_hid, num_input_channels, kernel_size=3, padding=1, stride=2, output_padding=1), # 32x32 <= 16x16
|
||
|
|
nn.Tanh(),
|
||
|
|
# nn.Sigmoid(),
|
||
|
|
)
|
||
|
|
# You code goes here.
|
||
|
|
|
||
|
|
def forward(self, x):
|
||
|
|
return self.net(x)
|
||
|
|
# You code goes here.
|
||
|
|
|
||
|
|
|
||
|
|
# # Combining Encoder and Decoder
|
||
|
|
# ## Loss Function: Mean Squared Error (MSE)
|
||
|
|
#
|
||
|
|
# For our loss function, we opt for the Mean Squared Error (MSE). MSE is particularly effective in emphasizing the significance of accurately predicting pixel values that are substantially misestimated by the network. For instance, a minor deviation, such as predicting 127 instead of 128, is deemed less critical. However, larger discrepancies, like confusing a pixel value of 0 with 128, are considered more severe and detrimental to the reconstruction quality.
|
||
|
|
#
|
||
|
|
# Unlike Variational Autoencoders (VAEs) that predict the probability for each pixel value, we employ MSE as a straightforward distance measure. This approach significantly reduces the number of parameters, streamlining the training process. To enhance our understanding of the per-pixel performance, we calculate the summed squared error, averaged across the batch dimension. It's important to note that alternative aggregations (mean or sum) yield equivalent outcomes in terms of resulting parameters.
|
||
|
|
#
|
||
|
|
# ### Limitations of MSE
|
||
|
|
#
|
||
|
|
# Despite its advantages, MSE is not without drawbacks. Primarily, it tends to produce blurrier images, as it inherently removes small noise and high-frequency patterns, which contribute minimally to the overall error. To mitigate this and achieve more realistic reconstructions, integrating Generative Adversarial Networks (GANs) with autoencoders has proven effective. This hybrid approach is explored in various studies ([example 1](https://arxiv.org/abs/1704.02304), [example 2](https://arxiv.org/abs/1511.05644), and [slides](http://elarosca.net/slides/iccv_autoencoder_gans.pdf)).
|
||
|
|
#
|
||
|
|
# Furthermore, MSE may not always accurately reflect visual similarity between images. A case in point is when an autoencoder produces an image that is slightly shifted—despite the near-identical appearance, the MSE can significantly increase, showcasing a limitation in capturing true visual fidelity. A potential solution involves leveraging a pre-trained CNN to measure distance based on visual features extracted from lower layers, offering a more nuanced comparison than pixel-level MSE.
|
||
|
|
#
|
||
|
|
|
||
|
|
# In[134]:
|
||
|
|
|
||
|
|
|
||
|
|
class Autoencoder(nn.Module):
|
||
|
|
|
||
|
|
def __init__(self,
|
||
|
|
base_channel_size: int,
|
||
|
|
latent_dim: int,
|
||
|
|
encoder_class : object = Encoder,
|
||
|
|
decoder_class : object = Decoder,
|
||
|
|
num_input_channels: int = 3,
|
||
|
|
width: int = 32,
|
||
|
|
height: int = 32):
|
||
|
|
super().__init__()
|
||
|
|
# Creating encoder and decoder
|
||
|
|
self.encoder = encoder_class(num_input_channels, base_channel_size, latent_dim)
|
||
|
|
self.decoder = decoder_class(num_input_channels, base_channel_size, latent_dim)
|
||
|
|
# Example input array needed for visualizing the graph of the network
|
||
|
|
self.example_input_array = torch.zeros(2, num_input_channels, width, height)
|
||
|
|
|
||
|
|
def forward(self, x):
|
||
|
|
z = self.encoder(x)
|
||
|
|
x_hat = self.decoder(z)
|
||
|
|
return x_hat
|
||
|
|
|
||
|
|
def _get_reconstruction_loss(self, batch):
|
||
|
|
x = batch # We do not need the labels
|
||
|
|
x_hat = self.forward(x)
|
||
|
|
loss = F.mse_loss(x, x_hat, reduction="none")
|
||
|
|
loss = loss.sum(dim=[1,2,3]).mean(dim=[0])
|
||
|
|
return loss
|
||
|
|
|
||
|
|
|
||
|
|
# # Utility code for comparing Images
|
||
|
|
|
||
|
|
# In[14]:
|
||
|
|
|
||
|
|
|
||
|
|
def compare_imgs(img1, img2, title_prefix=""):
|
||
|
|
# Calculate MSE loss between both images
|
||
|
|
loss = F.mse_loss(img1, img2, reduction="sum")
|
||
|
|
# Plot images for visual comparison
|
||
|
|
grid = torchvision.utils.make_grid(torch.stack([img1, img2], dim=0), nrow=2, normalize=True)
|
||
|
|
grid = grid.permute(1, 2, 0)
|
||
|
|
plt.figure(figsize=(4,2))
|
||
|
|
plt.title(f"{title_prefix} Loss: {loss.item():4.2f}")
|
||
|
|
plt.imshow(grid)
|
||
|
|
plt.axis('off')
|
||
|
|
plt.show()
|
||
|
|
|
||
|
|
for i in range(2):
|
||
|
|
# Load example image
|
||
|
|
img, _ = train_dataset[i]
|
||
|
|
img_mean = img.mean(dim=[1,2], keepdims=True)
|
||
|
|
|
||
|
|
# Shift image by one pixel
|
||
|
|
SHIFT = 1
|
||
|
|
img_shifted = torch.roll(img, shifts=SHIFT, dims=1)
|
||
|
|
img_shifted = torch.roll(img_shifted, shifts=SHIFT, dims=2)
|
||
|
|
img_shifted[:,:1,:] = img_mean
|
||
|
|
img_shifted[:,:,:1] = img_mean
|
||
|
|
compare_imgs(img, img_shifted, "Shifted -")
|
||
|
|
|
||
|
|
# Set half of the image to zero
|
||
|
|
img_masked = img.clone()
|
||
|
|
img_masked[:,:img_masked.shape[1]//2,:] = img_mean
|
||
|
|
compare_imgs(img, img_masked, "Masked -")
|
||
|
|
|
||
|
|
|
||
|
|
# # Task2
|
||
|
|
# Add training code to train the AutoEncoder
|
||
|
|
|
||
|
|
# In[2]:
|
||
|
|
|
||
|
|
|
||
|
|
# for batch in tqdm(train_loader, total=len(train_loader)):
|
||
|
|
import torch.optim as optim
|
||
|
|
|
||
|
|
model = Autoencoder(64, 128, ) # you code here
|
||
|
|
model.to(device)
|
||
|
|
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # your code here
|
||
|
|
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min') # your code here, can use ReduceLROnPlateau
|
||
|
|
# Write training loop here
|
||
|
|
|
||
|
|
loss_fn = nn.MSELoss()
|
||
|
|
|
||
|
|
n_epoch = 40
|
||
|
|
model.train()
|
||
|
|
for epoch in range(n_epoch):
|
||
|
|
print(f"\nEpoch {epoch}:")
|
||
|
|
|
||
|
|
avg_loss = 0
|
||
|
|
|
||
|
|
for i, data in enumerate(train_loader):
|
||
|
|
inputs, _ = data
|
||
|
|
|
||
|
|
inputs = inputs.cuda()
|
||
|
|
|
||
|
|
loss = model._get_reconstruction_loss(inputs) #loss_fn(outputs, inputs)
|
||
|
|
|
||
|
|
optimizer.zero_grad()
|
||
|
|
|
||
|
|
loss.backward()
|
||
|
|
|
||
|
|
optimizer.step()
|
||
|
|
|
||
|
|
avg_loss += loss
|
||
|
|
|
||
|
|
print(f'\rBatch: {i}: Loss:{loss} avg_Loss: {avg_loss/(i + 1)} ', end='')
|
||
|
|
|
||
|
|
scheduler.step(loss)
|
||
|
|
|
||
|
|
|
||
|
|
# In[144]:
|
||
|
|
|
||
|
|
|
||
|
|
def visualize_reconstructions(model, input_imgs):
|
||
|
|
# Reconstruct images
|
||
|
|
model.eval()
|
||
|
|
with torch.no_grad():
|
||
|
|
reconst_imgs = model(input_imgs.to(device))
|
||
|
|
reconst_imgs = reconst_imgs.cpu()
|
||
|
|
|
||
|
|
# Plotting
|
||
|
|
imgs = torch.stack([input_imgs, reconst_imgs], dim=1).flatten(0,1)
|
||
|
|
grid = torchvision.utils.make_grid(imgs, nrow=4, normalize=True)
|
||
|
|
grid = grid.permute(1, 2, 0)
|
||
|
|
plt.figure(figsize=(7,4.5))
|
||
|
|
plt.title(f"Reconstructed from model")
|
||
|
|
plt.imshow(grid)
|
||
|
|
plt.axis('off')
|
||
|
|
plt.show()
|
||
|
|
|
||
|
|
input_imgs = get_train_images(6)
|
||
|
|
visualize_reconstructions(model, input_imgs)
|
||
|
|
|
||
|
|
|
||
|
|
# # Masked AutoEncoder
|
||
|
|
# The follow code are the demonstration of Masked Autoencoder implementation and visualization
|
||
|
|
|
||
|
|
# # Import Necessary Libraries
|
||
|
|
|
||
|
|
# In[4]:
|
||
|
|
|
||
|
|
|
||
|
|
import sys
|
||
|
|
import os
|
||
|
|
import requests
|
||
|
|
|
||
|
|
import torch
|
||
|
|
import numpy as np
|
||
|
|
|
||
|
|
import matplotlib.pyplot as plt
|
||
|
|
from PIL import Image
|
||
|
|
|
||
|
|
# check whether run in Colab
|
||
|
|
if 'google.colab' in sys.modules:
|
||
|
|
print('Running in Colab.')
|
||
|
|
get_ipython().system('pip3 install timm==0.4.5 # 0.3.2 does not work in Colab')
|
||
|
|
get_ipython().system('git clone https://github.com/facebookresearch/mae.git')
|
||
|
|
sys.path.append('./mae')
|
||
|
|
else:
|
||
|
|
sys.path.append('./mae')
|
||
|
|
import models_mae
|
||
|
|
|
||
|
|
|
||
|
|
# # Build up necessary utillities
|
||
|
|
|
||
|
|
# In[131]:
|
||
|
|
|
||
|
|
|
||
|
|
# define the utils
|
||
|
|
|
||
|
|
imagenet_mean = np.array([0.485, 0.456, 0.406])
|
||
|
|
imagenet_std = np.array([0.229, 0.224, 0.225])
|
||
|
|
|
||
|
|
def show_image(image, title=''):
|
||
|
|
# image is [H, W, 3]
|
||
|
|
assert image.shape[2] == 3
|
||
|
|
plt.imshow(torch.clip((image * imagenet_std + imagenet_mean) * 255, 0, 255).int())
|
||
|
|
plt.title(title, fontsize=16)
|
||
|
|
plt.axis('off')
|
||
|
|
return
|
||
|
|
|
||
|
|
def prepare_model(chkpt_dir, arch='mae_vit_large_patch16'):
|
||
|
|
# build model
|
||
|
|
model = getattr(models_mae, arch)()
|
||
|
|
# load model
|
||
|
|
checkpoint = torch.load(chkpt_dir, map_location='cpu')
|
||
|
|
msg = model.load_state_dict(checkpoint['model'], strict=False)
|
||
|
|
print(msg)
|
||
|
|
return model
|
||
|
|
|
||
|
|
def run_one_image(img, model):
|
||
|
|
x = torch.tensor(img)
|
||
|
|
|
||
|
|
# make it a batch-like
|
||
|
|
x = x.unsqueeze(dim=0)
|
||
|
|
x = torch.einsum('nhwc->nchw', x)
|
||
|
|
|
||
|
|
# run MAE
|
||
|
|
loss, y, mask = model(x.float(), mask_ratio= 0.75)
|
||
|
|
y = model.unpatchify(y)
|
||
|
|
y = torch.einsum('nchw->nhwc', y).detach().cpu()
|
||
|
|
|
||
|
|
# visualize the mask
|
||
|
|
mask = mask.detach()
|
||
|
|
mask = mask.unsqueeze(-1).repeat(1, 1, model.patch_embed.patch_size[0]**2 *3) # (N, H*W, p*p*3)
|
||
|
|
mask = model.unpatchify(mask) # 1 is removing, 0 is keeping
|
||
|
|
mask = torch.einsum('nchw->nhwc', mask).detach().cpu()
|
||
|
|
|
||
|
|
x = torch.einsum('nchw->nhwc', x)
|
||
|
|
|
||
|
|
# masked image
|
||
|
|
im_masked = x * (1 - mask)
|
||
|
|
|
||
|
|
# MAE reconstruction pasted with visible patches
|
||
|
|
im_paste = x * (1 - mask) + y * mask
|
||
|
|
|
||
|
|
# make the plt figure larger
|
||
|
|
plt.rcParams['figure.figsize'] = [24, 24]
|
||
|
|
|
||
|
|
plt.subplot(1, 4, 1)
|
||
|
|
show_image(x[0], "original")
|
||
|
|
|
||
|
|
plt.subplot(1, 4, 2)
|
||
|
|
show_image(im_masked[0], "masked")
|
||
|
|
|
||
|
|
plt.subplot(1, 4, 3)
|
||
|
|
show_image(y[0], "reconstruction")
|
||
|
|
|
||
|
|
plt.subplot(1, 4, 4)
|
||
|
|
show_image(im_paste[0], "reconstruction + visible")
|
||
|
|
|
||
|
|
plt.show()
|
||
|
|
|
||
|
|
|
||
|
|
# # Load one image
|
||
|
|
|
||
|
|
# In[189]:
|
||
|
|
|
||
|
|
|
||
|
|
# load an image
|
||
|
|
img_url = 'https://user-images.githubusercontent.com/11435359/147738734-196fd92f-9260-48d5-ba7e-bf103d29364d.jpg' # fox, from ILSVRC2012_val_00046145
|
||
|
|
# img_url = 'https://user-images.githubusercontent.com/11435359/147743081-0428eecf-89e5-4e07-8da5-a30fd73cc0ba.jpg' # cucumber, from ILSVRC2012_val_00047851
|
||
|
|
img = Image.open(requests.get(img_url, stream=True).raw)
|
||
|
|
img = img.resize((224, 224))
|
||
|
|
img = np.array(img) / 255.
|
||
|
|
|
||
|
|
assert img.shape == (224, 224, 3)
|
||
|
|
|
||
|
|
# normalize by ImageNet mean and std
|
||
|
|
img = img - imagenet_mean
|
||
|
|
img = img / imagenet_std
|
||
|
|
|
||
|
|
plt.rcParams['figure.figsize'] = [5, 5]
|
||
|
|
show_image(torch.tensor(img))
|
||
|
|
|
||
|
|
|
||
|
|
# In[141]:
|
||
|
|
|
||
|
|
|
||
|
|
# Patch for numpy error
|
||
|
|
np.float = float
|
||
|
|
np.int = int #module 'numpy' has no attribute 'int'
|
||
|
|
np.object = object #module 'numpy' has no attribute 'object'
|
||
|
|
np.bool = bool #module 'numpy' has no attribute 'bool'
|
||
|
|
# This is an MAE model trained with pixels as targets for visualization (ViT-Large, training mask ratio=0.75)
|
||
|
|
|
||
|
|
# download checkpoint if not exist
|
||
|
|
get_ipython().system('wget -nc https://dl.fbaipublicfiles.com/mae/visualize/mae_visualize_vit_large.pth')
|
||
|
|
|
||
|
|
chkpt_dir = 'mae_visualize_vit_large.pth'
|
||
|
|
model_mae = prepare_model(chkpt_dir, 'mae_vit_large_patch16')
|
||
|
|
print('Model loaded.')
|
||
|
|
|
||
|
|
|
||
|
|
mine_img = Image.open('./st2/6644818.png', formats=('PNG',)).convert('RGB')# Image.open(requests.get(img_url, stream=True).raw)
|
||
|
|
|
||
|
|
# mine_img.show()
|
||
|
|
mine_img = mine_img.resize((224, 224))
|
||
|
|
|
||
|
|
mine_img = np.array(mine_img) / 255.
|
||
|
|
|
||
|
|
# print(mine_img.shape, mine_img[0][0])
|
||
|
|
|
||
|
|
assert mine_img.shape == (224, 224, 3)
|
||
|
|
|
||
|
|
# normalize by ImageNet mean and std
|
||
|
|
mine_img = mine_img - imagenet_mean
|
||
|
|
mine_img = mine_img / imagenet_std
|
||
|
|
|
||
|
|
plt.rcParams['figure.figsize'] = [5, 5]
|
||
|
|
show_image(torch.tensor(mine_img))
|
||
|
|
|
||
|
|
|
||
|
|
import pandas as pd
|
||
|
|
|
||
|
|
d = pd.read_csv('st2/6644818/shuffle_info.csv', header=None)
|
||
|
|
|
||
|
|
ids_keep = torch.Tensor(eval(d.loc[0][1])).type(torch.int64)
|
||
|
|
ids_restore = torch.Tensor(eval(d.loc[1][1])).type(torch.int64)
|
||
|
|
|
||
|
|
def masking(self, x):
|
||
|
|
N, L, D = x.shape # batch, length, dim
|
||
|
|
return torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D)) # Creates the masked images
|
||
|
|
|
||
|
|
def forward_encoder(self, x):
|
||
|
|
# embed patches
|
||
|
|
x = self.patch_embed(x)
|
||
|
|
|
||
|
|
# add pos embed w/o cls token
|
||
|
|
x = x + self.pos_embed[:, 1:, :]
|
||
|
|
|
||
|
|
x = masking(self, x)
|
||
|
|
|
||
|
|
# append cls token
|
||
|
|
cls_token = self.cls_token + model.pos_embed[:, :1, :]
|
||
|
|
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
|
||
|
|
x = torch.cat((cls_tokens, x), dim=1)
|
||
|
|
|
||
|
|
# apply Transformer blocks
|
||
|
|
for blk in self.blocks:
|
||
|
|
x = blk(x)
|
||
|
|
x = self.norm(x)
|
||
|
|
|
||
|
|
return x
|
||
|
|
|
||
|
|
def restore_one_image(img, model):
|
||
|
|
x = torch.tensor(img)
|
||
|
|
|
||
|
|
# make it a batch-like
|
||
|
|
x = x.unsqueeze(dim=0)
|
||
|
|
x = torch.einsum('nhwc->nchw', x)
|
||
|
|
|
||
|
|
temp_x = forward_encoder(model, x.float())
|
||
|
|
|
||
|
|
y = model.forward_decoder(temp_x, ids_restore)
|
||
|
|
y = model.unpatchify(y)
|
||
|
|
y = torch.einsum('nchw->nhwc', y).detach().cpu()
|
||
|
|
|
||
|
|
x = torch.einsum('nchw->nhwc', x)
|
||
|
|
|
||
|
|
# make the plt figure larger
|
||
|
|
plt.rcParams['figure.figsize'] = [12, 12]
|
||
|
|
|
||
|
|
plt.subplot(1, 2, 1)
|
||
|
|
show_image(x[0], "original")
|
||
|
|
|
||
|
|
plt.subplot(1, 2, 2)
|
||
|
|
show_image(y[0], "reconstruction")
|
||
|
|
|
||
|
|
plt.show()
|
||
|
|
|
||
|
|
torch.manual_seed(5)
|
||
|
|
print('MAE with pixel reconstruction:')
|
||
|
|
restore_one_image(mine_img, model_mae)
|
||
|
|
|
||
|
|
|
||
|
|
# In[ ]:
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
|